ARTH TASK-1
The giant companies like Google, Facebook, etc., receives a large amount of data every second and will be updated and available to all of us in seconds. How those companies achieve that much storage to store data, processor for I/O performance ?
Google receives the following number of search requests on an average everyday
Google currently processes 20 PetaBytes of data every day.(1 PetaByte = 1024 TeraBytes)
Facebook revealed that its system processes 2.5 billion pieces of content and 500+ terabytes of data each day
Everyday Facebook feed it's data beast with mounds of information.
Every one minute,
136,000 photos are uploaded
510,000 comments are posted
Recommended by LinkedIn
293,000 status updates are posted
The problem can be called as BigData and can be solved by using Hadoop.
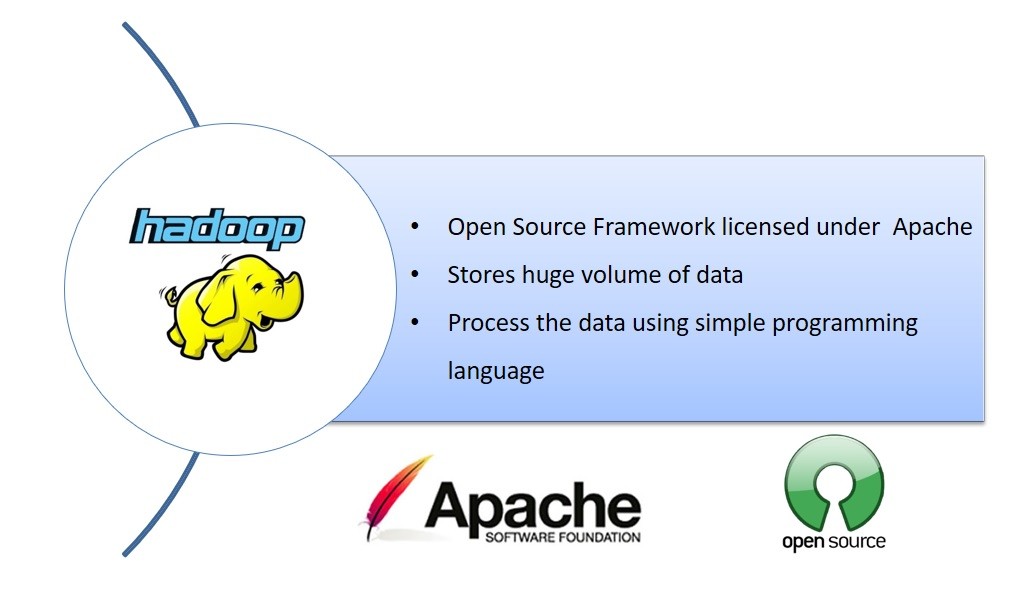
What is Hadoop ?
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.
How Facebook handles all users data ?
With 1 Billion active users, Facebook has one of the largest data warehouses .
"Facebook runs the biggest Hadoop cluster" says Jay Parikh, Vice President Infrastructure Engineering, Facebook
Basically , Facebook runs the biggest Hadoop cluster that goes beyond 4,000 machines and storing more than hundreds of millions of gigabytes.
Hadoop provides a common infrastructure for Facebook with reliability and efficiency.
Beginning with searching, log processing, recommendation systems, and data warehousing , to and image analysis , Hadoop is empowering this social networking platform in each and every way possible.
Facebook Messenger is based on Apache HBase, which has a layered architecture that supports plethora of messages in a single day.


