Exploring PageRank algorithm in GraphX library
GraphX : A component of Apache Spark for graph parallel computation
GraphX is a graph computation library provided by Spark. The power of GraphX comes from the inbuilt algorithms that can be applied to various business scenarios. In this article we will explore few design details specific to PageRank implementation in GraphX.
PageRank algorithm (https://en.wikipedia.org/wiki/PageRank) was originally developed by Larry Page and Sergey Brin to rank websites for Google. Though the original intent was ranking web pages, it can be applied to measure the influence of vertices in any network graph.
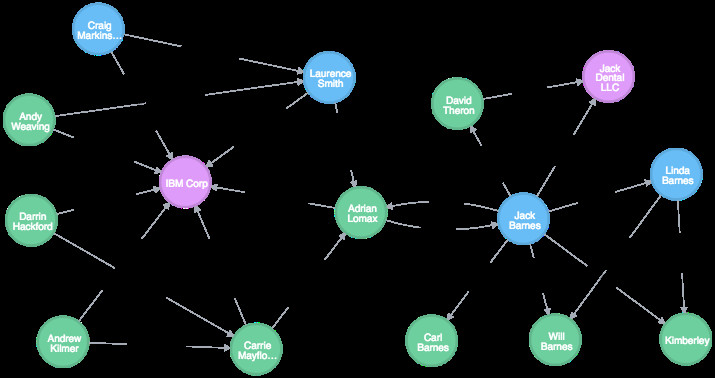
We will start with a modified sub-graph of the sample data developed in an earlier post www.garudax.id/hp/update/61878459858053980. In this sub-graph (shown above) we are only going to consider sample data of one company for corporate relationships and of one individual for family and social relationships.
Schema: defining bidirectional relationships
Usually for storage of bidirectional relationships in Neo4j or other graph databases, its recommended to design graph data model in such a way that traversing single edge in both directions is utilized as explained in this article http://graphaware.com/neo4j/2013/10/11/neo4j-bidirectional-relationships.htm and shown below.

However, the above design will not work for GraphX inbuilt algorithms. The property graph in GraphX is a directed multi-graph. Each edge is directed and defines a unidirectional relationship. For an algorithm like PageRank to work correctly you will need two edges for bidirectional relationship going in each direction. For example if Jack and Adrian are friends then for GraphX you will need to define two edges, one depicting Jack is friend of Adrian and another depicting Adrian is a friend of Jack.

Schema: Defining unidirectional relationships
The direction of the edge in unidirectional relationship will depend on business semantics. If the business rules determine that a company (e.g. HR policy) has influence on its employees decision but not vice versa than that would be a uni-directional relationship. In that case the direction of relationship should be able to capture business influence correctly. For PageRank to give desired results draw the direction towards the influencer (backlink or incoming links). Alternately, if directions of edges are pointed in the same direction as influence, than you can use reverse PageRank (Reverse PageRank is PageRank calculated after reversing the directions of all the edges between vertices). We will see an example of both below
Defining Class hierarchy for vertices and edges in Scala.
Business graphs are complex and can contain vertices of many different types. For example, in the graph above we have vertices representing Client, Prospects, and Company. However in GraphX the Graph definition is parameterized over the vertex (VD) and edge (ED) types as can be seen from the class definition of Graph class. This means only one vertex type can be parameterized.
package org.apache.spark.graphx
....
/**
….
* @tparam VD the vertex attribute type
* @tparam ED the edge attribute type
*/abstract. class. Graph[VD: ClassTag, ED: ClassTag] protected () extends. Serializable{
....
We can solve this particular problem by defining a class hierarchy which extends base class VertexProperty as shown below.
package org.wm
....
/class. VertexProperty(var inDeg:Int, var outDeg:Int, var pageRank:Double) extends. Serializable
/case. class. Client(in:Int, out:Int, pr:Double, val name:String, valNet_Worth:Double, val fico:Int, val age:Int) extends. VertexProperty(in, out, pr)
/case. class. Prospect(in: Int, out: Int, pr:Double, val name:String, val Net_Worth:Double, val fico:Int, val age:Int) extends. VertexProperty(in, out, pr)
/case. class. Company(in: Int, out: Int, pr:Double, val name:String, val employees:Int, val headquarter:String) extends. VertexProperty(in, out, pr)
Once the class hierarchy is defined the Graph can be built and parameterized [VD] with VertexProperty.
/def. buildGraphUniDirectional(sc: SparkContext): Graph[VertexProperty, EdgeProperty] = {
val vertexArray = Array(
(1L, Client(0, 0, 0, "Jack Barnes", 9, 750, 52).asInstanceOf[VertexProperty]),
(2L, Client(0, 0, 0, "Linda Barnes", 7, 825, 48).asInstanceOf[VertexProperty]),
(3L, Prospect(0, 0, 0, "Kimberley Barnes", 2, 600, 23).asInstanceOf[VertexProperty]),
(6L, Company(0, 0, 0, "Jack Dental LLC", 4, "Manhattan NY").asInstanceOf[VertexProperty]),
....
val edgeArray = Array(
Edge(1L, 2L, SPOUSE(100, 9).asInstanceOf[EdgeProperty]),
Edge(1L, 3L, FATHER(100, 5).asInstanceOf[EdgeProperty]),
Edge(1L, 7L, PARTNER().asInstanceOf[EdgeProperty]),
....
val vertexRDD: RDD[(Long, VertexProperty)] = sc.parallelize(vertexArray)
val edgeRDD: RDD[Edge[EdgeProperty]] = sc.parallelize(edgeArray)
val graph: Graph[VertexProperty, EdgeProperty] = Graph(vertexRDD, edgeRDD)
return graph
}
Running the actual PageRank algorithm is quite straightforward in GraphX
val pageRank = graph.staticPageRank(5).cache
Joining this information with original property graph is little tricky, as it needs to identify the type of vertex class due to our class hierarchy. It can be done as shown below.
/def. addPageRank(graph: Graph[VertexProperty, EdgeProperty]): Graph[VertexProperty, EdgeProperty] = {
val pageRank = graph.staticPageRank(5).cache
val graphWithPageRank = graph.outerJoinVertices(pageRank.vertices) {
case (vid, v, pageRank) => {
var vp: VertexProperty = null
if (v.getClass().getName().equals("org.wm.Client")) {
val cv = v.asInstanceOf[Client]
vp = Client(cv.in, cv.out, pageRank.getOrElse(0.0), cv.name, cv.Net_Worth, cv.fico, cv.age)
} elseif (v.getClass().getName().equals("org.wm.Prospect")) {
val pros = v.asInstanceOf[Prospect]
vp = Prospect(pros.in, pros.out, pageRank.getOrElse(0.0), pros.name, pros.Net_Worth, pros.fico, pros.age)
} elseif (v.getClass().getName().equals("org.wm.Company")) {
val com = v.asInstanceOf[Company]
vp = Company(com.in, com.out, pageRank.getOrElse(0.0), com.name, com.employees, com.headquarter)
}vp
}
}
return graphWithPageRank
}
Running the code above will return a graph with PageRank populated in its vertices. Below is a table of results with PageRank, Reverse PageRank and one more scenario where all relationships are defined as bidirectional.

The table below shows how PageRank is affected after adding another relationship i. e. friendship between Jack and Andrews. The incoming and outgoing links are also updated.

Summary: The application of PageRank extends beyond ranking of websites and can be used to find authority of vertices in any network graph. GraphX from Apache Spark provides an inbuilt implementation of PageRank which can be run at scale on any big data cluster where Spark is available. This post discusses some of the design and implementation details involved in running PageRank. For interpretation of these results and its business application please see an accompanying post.
Useful Links:
- For details on how to transform relational data in to graphical representation please see this post.
- Apache Spark is a fast engine for large scale data processing. I have used Spark version 2.0 for this article.
- For moving data to and fro between Spark and Neo4j check out Neo4j-Spark-Connector.
- The original PageRank paper published by Sergey Brin and Larry Page.