Enhancing FastAPI Performance with HTTP/2 and QUIC (HTTP/3) for Efficient Machine Learning Inference
Machine learning (ML) inference systems must handle large requests while maintaining low latency and high throughput. With HTTP/1.1, FastAPI handles client-server communication well, but with the increasing demand for performance, it’s essential to consider upgrading to HTTP/2 and QUIC (HTTP/3). These protocols provide significant benefits in optimizing the performance of APIs that handle numerous requests in real-time, such as in ML inference.
In this article, we will explore how using HTTP/2 and QUIC can improve the performance of FastAPI for ML inference.
Why HTTP/2 and QUIC for ML Inference?
Both HTTP/2 and QUIC (HTTP/3) are optimized for reducing latency, multiplexing connections, and improving overall throughput — all essential for machine learning systems that process requests rapidly. Here are the advantages:
By using HTTP/2 and QUIC with FastAPI, you can significantly reduce response times and improve throughput for real-time ML inference.
Setting Up FastAPI with HTTP/2 and QUIC
Step 1: Install Required Dependencies
First, ensure you have FastAPI and Uvicorn installed. Uvicorn supports HTTP/2 when the standard package is installed.
pip install fastapi uvicorn[standard]
Alternatively, if you want to take advantage of QUIC, you can use Hypercorn, which supports HTTP/3 as well as HTTP/2.
pip install hypercorn
Step 2: Basic FastAPI Setup
Here’s a simple FastAPI application that performs ML inference, such as image classification:
from fastapi import FastAPI, UploadFile
import uvicorn
app = FastAPI()
@app.post("/predict")
async def predict(file: UploadFile):
# Simulate ML inference process
image = await file.read()
# Your model inference logic goes here
result = {"prediction": "cat", "confidence": 0.95}
return result
Step 3: Enabling HTTP/2 with Uvicorn
To run your FastAPI application with HTTP/2 enabled, use the following command with Uvicorn, ensuring that TLS is set up (HTTP/2 requires encryption):
uvicorn app:app --host 0.0.0.0 --port 8000 --ssl-keyfile=key.pem --ssl-certfile=cert.pem --http2
You will need to provide valid SSL certificates (key.pem and cert.pem) because most browsers require TLS for HTTP/2 connections.
Step 4: Enabling HTTP/2 and QUIC with Hypercorn
Hypercorn supports both HTTP/2 and HTTP/3 (QUIC). To enable them, run:
hypercorn app:app --bind 0.0.0.0:8000 --certfile=cert.pem --keyfile=key.pem --quic
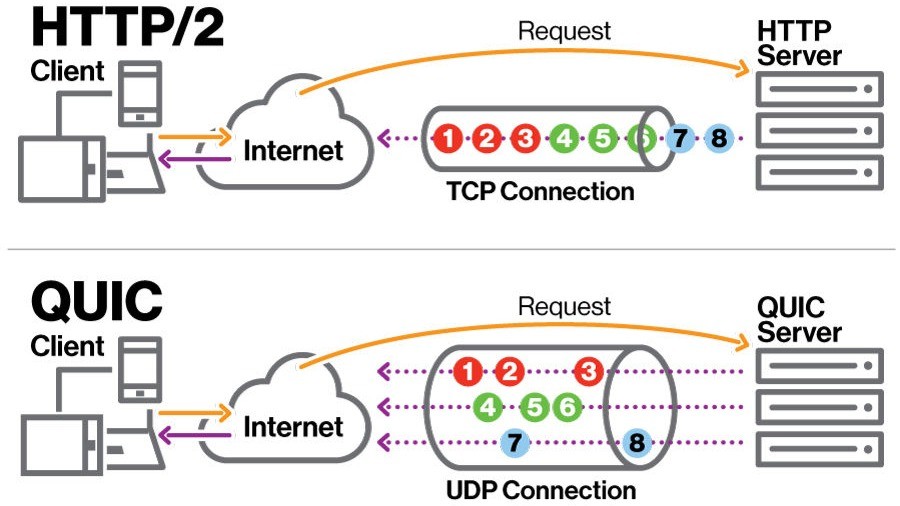
This command allows you to use HTTP/2 and HTTP/3 depending on the client’s capabilities, enabling faster communication. QUIC is particularly beneficial for networks with high packet loss or latency, thanks to using UDP instead of TCP.
Performance Optimizations for ML Inference
With HTTP/2 and QUIC set up, you can further optimize your FastAPI service for machine learning inference by implementing these strategies:
Recommended by LinkedIn
1. Asynchronous Programming
FastAPI supports asynchronous programming by default. Using asynchronous I/O allows you to process multiple requests without blocking operations, which is especially important when handling numerous inference requests.
2. Batch Inference
If your model supports it, group multiple inference requests into a batch to process them in a single pass. This improves efficiency, especially with deep learning models that involve complex computations.
3. Stream Responses
For models that return large amounts of data (e.g., image generation or video frames), use FastAPI’s streaming capabilities. This allows you to send data in chunks, reducing the waiting time for clients.
from fastapi import StreamingResponse
@app.get("/stream")
async def stream_inference():
def inference_stream():
# Simulate inference process and yield data in chunks
for _ in range(10):
yield b'some data\n'
return StreamingResponse(inference_stream())
4. Caching
Implement caching mechanisms for frequently requested inference results. Tools like Redis or Memcached can drastically reduce latency when repeated requests need to serve the same results.
5. Model Preloading
Ensure that your ML models are preloaded when the application starts. Reloading models for each request will significantly increase the latency, especially for large models. Keep the models in memory for fast access.
6. Prioritize Critical Inference Requests
With HTTP/2 and QUIC, you can prioritize critical requests. For instance, by setting priority flags, real-time inferences can be prioritized over batch requests.
7. Use Server Push (HTTP/2)
Server push allows your FastAPI service to send resources to the client proactively before they are requested. In ML inference, you can use this to preload common assets, like inference results or static files, improving performance.
Why Choose QUIC (HTTP/3) for ML Inference?
QUIC (HTTP/3) is particularly useful for ML inference systems under high network load, where packet loss or latency is a concern. Since QUIC uses UDP, it bypasses the delays caused by TCP’s connection setup and congestion control, resulting in faster response times. This can be critical for real-time inference systems, such as those processing video streams or live data.
Key benefits of QUIC for ML inference include:
Conclusion
Upgrading FastAPI to use HTTP/2 and QUIC (HTTP/3) can lead to substantial performance gains, particularly in machine learning inference systems. These protocols offer advanced features like multiplexing, header compression, and optimized transport mechanisms, allowing your service to handle high-traffic scenarios efficiently.
With HTTP/2, you benefit from reduced latency and better resource utilization, while QUIC offers faster and more reliable connections, especially in challenging network conditions. Combine these protocols with best practices such as asynchronous I/O, caching, and streaming responses to build an efficient, scalable ML inference API.
By leveraging these technologies, you can create an API that meets the demands of modern machine learning applications, ensuring fast and reliable inference at scale.
Original Article