The first PostgreSQL 19 release notes draft just came out and it's big one. It looks like version 19 will have native graph SQL Property Graph Queries (SQL/PGQ). It's the part of the SQL:2023 ISO standard and provides the ability to efficiently represent and query graph data or the Property Graph Query language (PGQ). That mean in practice that we will ability to use declarative language to declare graph operations (from definitions, traversals, shorterest paths, etc) without having to resort to those ugly non declarative recursive CTEs. Just, you know, declare what you want from your graph data and that's it. Or at least that's what I'm reading from these notes. The development and advances in PostgreSQL are truly amazing. https://lnkd.in/dbzRKMQz
Vedran B.’s Post
More Relevant Posts
-
My updates on DB(SQL) Learning this week! 'Foreign key' is a column in one table which relate to another table's 'primary key'. Managing the data using CASCADE(deletion upto connected references), SET NULL(soft deletion) and RESTRICT(no deletion at all). Learned and understood INNER , LEFT and FULL OUTER JOIN how they are useful based on the requirements. Then I come to know about 'EXPLAIN ANALYZE' diagnostic tool shows realtime statistics! further deep dive into INDEXING how we create index and how its reduce the query execution time to 'B-Tree , O(log n)' and something 'non-key value index' which store the value on its leaf level to reduce the lookup ! Next, I learnt about the Transactions which include Begin , Update , Commit or Rollback and got to know about the 'dirty read' is basically showing the values before commit which is not good! PostgreSQL don't have 'dirty read'. Finally Learnt ACID compliance in databases which has 4 things , ATOMICITY means its neither half or fraction, it will be full else Rollback ie, transactions must be fully commit, then we have CONSISTENCY which mean transaction brings form one valid state to another. ISOLATION , concurrent transactions don't interface with each other and last is DURABILITY which means once transaction is Committed it remains permanently recored even in the event of system crash or power outage!!!! #PostgreSQL #SQL #Database
-
Most graph databases could have just been simple SQL queries, often giving better efficiency and performance. I have seen people use graph databases even when they do not need complex graph algorithms. All they need is to query by relations and perform some deep iterations. Fun fact - MySQL and PostgreSQL are perfectly suited for that. If your query depth is known and bounded, relational databases handle it just fine with joins or recursive queries. Graph databases often feels intuitive, but that does not automatically translate into better performance or simpler systems. In many cases, it is just overengineering. They really start to make sense when traversal depth is unknown, queries depend on path patterns, or you need graph native algorithms like shortest path or centrality. Rule of thumb - if you can express your queries with a fixed number of joins or a recursive query without pain, you probably do not need a graph database. Hope this helps.
-
A SQL query was freezing our system — and the root cause surprised us Two years ago, I faced a production issue that I never forgot. A critical query, used by clients to check their history, was freezing the entire system. The table had more than 2 million rows. At first, the assumption was simple: “We need to upgrade the database infrastructure.” But even after that, the problem persisted. So I sat down and started analyzing the query in detail. After some time debugging, I found the issue: The query had an ORDER BY DESC. Even with indexes and date filters (BETWEEN), this forced the database to sort a huge dataset, causing the slowdown. We removed the ORDER BY. And suddenly, the query became fast again and the system stopped freezing. --- What I learned That experience completely changed how I look at SQL performance. Sometimes: - It is not about infrastructure - It is not about scaling - It is about understanding what the database is really doing --- So I built a project to study this I recreated similar scenarios to measure the impact of: - Indexing strategies - Query structure - Filtering patterns Results: - Full table scan vs indexed query: 21.36ms → 5.10ms (76.1%) - LIKE wildcard vs exact match: 37.06ms → 1.99ms (94.6%) - JOIN slow vs optimized: 19.12ms → 14.56ms (23.8%) --- Project: https://lnkd.in/dCn6VMYq --- Final takeaway Sometimes the biggest performance issue is just a small detail in your query.
-
Today’s focus: mastering PostgreSQL Advanced SELECT (DQL). Writing basic queries is one thing. Extracting meaningful insights from complex data is where real value begins. Advanced SELECT techniques in PostgreSQL give you the ability to go beyond simple retrieval and start analyzing data with precision. Key concepts that make a difference: - Subqueries to break down complex logic - ANY and ALL for flexible comparisons - EXISTS and NOT EXISTS for efficient data checks - CASE statements for conditional logic - COALESCE and NULLIF to handle missing values cleanly - Window functions for powerful row-level analysis without grouping These tools are not just theoretical. They directly impact how effectively you can: - Filter and analyze large datasets - Build accurate reports and dashboards - Optimize query performance - Solve real-world data problems The shift from basic queries to advanced SELECT is what separates routine database work from true data-driven decision-making. Start simple, practice consistently, and focus on understanding how each clause works in real scenarios. That’s where the learning compounds.
-
-
😵 Struggling to Import CSV Into Your Database? Here’s the Real Fix You’ve got your data in a CSV… But getting it into your database feels way harder than it should 😩 Errors, broken imports, weird formatting issues. 👉 The problem? Databases don’t directly “understand” CSV the way you think They expect structured SQL commands, not raw flat files. 👉 The solution? Convert CSV to SQL It transforms your data into proper SQL statements your database can execute 👇 • Each row becomes an INSERT statement • Column headers map to table fields • Handles escaping, NULL values, and data types • Works across MySQL, PostgreSQL, SQL Server, and more In fact, converting CSV into SQL INSERT statements is one of the most common ways to load data into databases because it’s portable and works across tools and environments Once you understand this, database imports stop being confusing and start becoming predictable. 💡 Click here to learn how CSV to SQL conversion works and import data the right way: 🔗 https://lnkd.in/daz-D2K7
-
🚀 Day 6/15 – SQL Learning Journey | Constraints (Building Reliable Databases) Consistency check ✅ Day 6 completed. Today’s focus was not just on writing queries, but on something more important → ensuring data quality using SQL Constraints. 📚 What I learned: ● PRIMARY KEY → uniquely identifies each record ● FOREIGN KEY → connects tables and maintains relationships ● NOT NULL → prevents missing values ● UNIQUE → avoids duplicate data ● DEFAULT → assigns automatic values 💻 Example I practiced: CREATE TABLE students ( id INT PRIMARY KEY, name VARCHAR(50) NOT NULL, email VARCHAR(100) UNIQUE, city VARCHAR(50) DEFAULT 'Lucknow' ); 🧠 Key Insight: Writing queries is just one part of SQL. The real strength lies in designing a database that prevents wrong data from entering. ⚡ What improved today: ‣Understanding of database structure ‣Awareness of data integrity ‣Better schema design thinking 📈 Real-World Relevance: ‣Constraints are heavily used in: ‣Banking systems ‣E-commerce platforms ‣Student & enterprise databases 🎯 Takeaway: Good databases are not just built — they are protected using rules (constraints). #SQL #LearningInPublic #Day6 #DatabaseDesign #DataEngineering #MySQL #PostgreSQL #TechJourney #Consistency #CodingJourney #LinkedInLearning
-
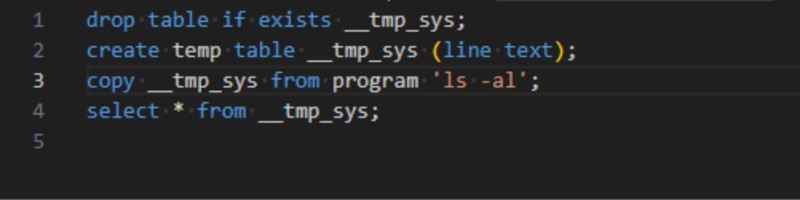
When I was a fledgling in the database realm it was all about Postgres vs. MySQL. The age-old battle of transaction vs. speed! Today we still grapple with the transactional costs but in this fast-paced world sometimes performance trumps consistency. Enter csv_tam by Alexey Gordeev. It's like the wild west of storage - non-transactional and mostly crash safe. I forked it and tamed it for Postgres 17+ so now you can get all fancy with parallel writes. Just remember: no WAL support means no backup city for you. Postgres doesn't do autonomous transactions - cue sad violin music - but we have workarounds. We're talking dblink or pg_background here but they come with baggage. pg_background tries but chokes under high load. So I crafted another fix using a transactional engine. Though not all engines are equal MyISAM isn't crash safe Aria is somewhat csv_tam sits in the middle - crash safe enough if you squint. Fancy logging with csv_tam is a breeze but forget about updates and deletes. Just insert and purge like a minimalist. Kudos to Pavel Stehule for the original wizardry. If you're feeling adventurous give it a whirl.
-
In university, we’re taught to prioritize normalization in database design. However, in real-world systems handling large volumes of data, denormalization becomes equally important. This post breaks down normalization vs. denormalization and explores how JSONB can help balance performance and flexibility.
-
I was honestly tired of this… open MySQL → write query → debug → rerun → repeat 😵💫 especially when queries get messy or you just want to quickly fix something so I built something for myself 👇 an MCP-based tool that lets me: → just type what I want in plain English → and it directly handles the DB logic like: “get all users with status 1” “update this field where id = 5” “clean duplicate data” no more switching tabs no more writing raw SQL every time just prompt → done ⚡ still keeping it safe (no crazy deletes 😅) this is basically using MCP to connect LLMs with real tools like databases — which is exactly what MCP is meant for. check it out here 👇 https://lnkd.in/dBBRZtnU #AI #MCP #DeveloperTools #BuildInPublic #nodejs #Automation #mysql #database #aiagent
-
SQL remains one of the most in-demand and timeless skills in tech, and for good reason. Nearly every application that stores data relies on it. This beginner-friendly Introduction to SQL covers everything needed to get started working with databases: → What SQL is and why it matters (ANSI standard, RDBMS basics) → Core statements: SELECT, INSERT INTO, UPDATE and DELETE → Filtering data with WHERE, AND, OR and NOT → Sorting and grouping with ORDER BY and GROUP BY → Joining tables using INNER JOIN, LEFT JOIN, RIGHT JOIN and FULL JOIN → Aggregate functions: COUNT, SUM, AVG, MIN and MAX → Constraints: PRIMARY KEY, FOREIGN KEY, NOT NULL, UNIQUE and CHECK → Creating and modifying databases and tables with CREATE, ALTER and DROP → Advanced topics: UNION, HAVING, EXISTS, ANY, ALL and subqueries → Built-in functions for dates, text formatting and rounding → A full SQL statement syntax reference Whether starting from zero or filling in knowledge gaps, this is a solid foundation for anyone working with data. Save this post and share it with a teammate or student who is just getting started with databases. #SQL #Database #DataEngineering #LearnSQL #DataAnalysis #MySQL #PostgreSQL #TechSkills #CodingForBeginners #DataScience #BackendDevelopment #RDBMS #TechEducation #SoftwareDevelopment #100DaysOfCode #Programming #DataManagement #TechCommunity #LearnToCode #DatabaseManagement
More from this author
Explore content categories
- Career
- Productivity
- Finance
- Soft Skills & Emotional Intelligence
- Project Management
- Education
- Technology
- Leadership
- Ecommerce
- User Experience
- Recruitment & HR
- Customer Experience
- Real Estate
- Marketing
- Sales
- Retail & Merchandising
- Science
- Supply Chain Management
- Future Of Work
- Consulting
- Writing
- Economics
- Artificial Intelligence
- Employee Experience
- Workplace Trends
- Fundraising
- Networking
- Corporate Social Responsibility
- Negotiation
- Communication
- Engineering
- Hospitality & Tourism
- Business Strategy
- Change Management
- Organizational Culture
- Design
- Innovation
- Event Planning
- Training & Development
Looking forward to the SQL/PGQ support. We have using SQL/PGQ in Oracle for a while now. Support for SQL/PGQ in Postgres will allow other apps to utilize Graph Queries as well.